You’ve probably waited on a slow Python script and thought, “There has to be a faster way.” And often, there is it called caching. Python Caching isn’t some advanced or obscure hack; it’s a practical, built-in way to skip redundant work and speed things up. Whether you're dealing with repeated function calls or expensive computations, caching lets you reuse earlier results instead of recalculating everything from scratch. It's like giving your code a memory. This article strips away the fluff and gets real about how caching works in Python, why it matters, and how to use it to improve performance in Python.
At its core, caching is simple: remember the answer once, so you don’t have to figure it out again. In Python, this idea turns into something surprisingly powerful. Imagine you’ve got a function that does some heavy lifting—say, crunches numbers or fetches data. If you call it repeatedly with the same input, Python will keep redoing the same work unless you step in. That’s where caching steps up. It stores the result the first time around, and the next time you ask for it, it hands it back instantly—no recalculations, no waiting.
Python makes this especially easy with the functools module. Inside it, the @lru_cache decorator is a small line of code that gives a big boost to speed. LRU stands for "Least Recently Used," and it does its job by tracking what results you've recently used, flushing the old ones out when the cache fills up too much.
Here’s what it looks like in action:
from functools import lru_cache
@lru_cache(maxsize=100)
def slow_function(x):
print("Running calculation...")
return x * x
Call slow_function(4) once, and it prints. Call it again—it's instant. The idea is not just about saving time. It's also about smart memory use, balancing speed and efficiency with just a few lines of code.
Python Caching becomes especially useful when your code performs expensive computations or repeatedly accesses external resources. One common example is data fetching. If your application frequently queries a database or calls an external API, caching the results can improve performance in Python by avoiding redundant fetches. Instead of hitting the server each time, you can retrieve stored responses, making the process faster and more efficient.
In data science, preprocessing large datasets often takes significant time. Filtering or transforming data repeatedly—especially during experimentation—can become a bottleneck. Caching those transformation functions using @lru_cache or a manual dictionary-based cache helps avoid reprocessing and speeds up iteration.
Web frameworks like Flask and Django use caching to improve load times. Dynamic pages often rebuild the same output with every request. Caching allows static parts of the site, like homepage content or navigation menus, to be stored temporarily in memory and reused. Flask-caching and similar tools make implementation seamless.
APIs with usage limits also benefit. If your app interacts with an API that has rate limits or billing per request, caching results for identical calls avoids extra charges and keeps you under usage thresholds.
Even in machine learning workflows, caching intermediate steps like feature extraction or cleaned data saves time during repeated model training or evaluation cycles.
Caching isn’t a one-size-fits-all solution. The way you cache depends on your use case. Let’s break down a few commonly used strategies that help improve performance in Python.
This is the most common and Pythonic form of caching. You use @lru_cache or implement your memoization logic using dictionaries. The decorator approach handles everything for you—hashing the input, managing memory, and evicting stale entries.
Sometimes, the built-in tools don’t cut it. You need more control. Maybe your function uses arguments that aren’t hashable (like lists or dictionaries), which makes them incompatible with @lru_cache. In such cases, you can manually implement caching logic with dictionaries. Just be careful with memory—since you’re handling cleanup yourself.

When you need your cache to last beyond a single script run, file-based caching is the way to go. Using Python’s pickle module or libraries like joblib, you can store results on disk and reload them later. It’s ideal for long-running tasks or large data science workflows.
For web apps or distributed setups, external caching tools like Redis or Memcached offer scalable solutions. With libraries like Redis-py, you can cache user sessions, database results, or API responses across systems, boosting speed and reducing server load without relying solely on in-memory data.
Each of these strategies contributes to performance and resource management, but choosing the right one depends on what you're optimizing for—speed, memory, persistence, or scale.
Caching in Python is powerful, but it must be used carefully to avoid common pitfalls. Always begin by measuring performance before and after caching. Tools like time, cProfile, or benchmarking libraries help you see real impact. Don’t just assume it’s faster—prove it.
Watch out for input types. The @lru_cache decorator only accepts immutable, hashable arguments. Passing lists or dictionaries will raise errors, so convert them or use manual caches.
Keep your cache size under control. Unlimited caching can bloat memory. Set a reasonable max size and consider time-based expiration for dynamic data, especially in web applications.
In multithreaded or multi-process environments, standard in-memory caching may fail. Use external caching tools like Redis for reliability.
Above all, remember that caching should enhance already efficient code—it’s not a fix for poorly written logic. Optimize your code first, then cache smartly to squeeze out the extra performance gains without introducing hidden issues.
Python Caching is a straightforward yet powerful technique to enhance your program’s efficiency. By storing the results of expensive or repeated operations, you can cut down on processing time and avoid unnecessary computations. Whether you’re working with data-heavy scripts, APIs, or web applications, caching helps improve performance in Python with minimal effort. With built-in tools like lru_cache and external solutions like Redis, you have flexible options to choose from. Implement caching wisely, and your code will run smoother and smarter.

Explore a detailed comparison of Neo4j vs. Amazon Neptune for data engineering projects. Learn about their features, performance, scalability, and best use cases to choose the right graph database for your system

Discover how DataRobot training empowers citizen data scientists with easy tools to boost data skills and workplace success

Understand how logarithms and exponents in complexity analysis impact algorithm efficiency. Learn how they shape algorithm performance and what they mean for scalable code

Learn how process industries can catch up in AI using clear steps focused on data, skills, pilot projects, and smart integration

How to compute vector embeddings with LangChain and store them efficiently using FAISS or Chroma. This guide walks you through embedding generation, storage, and retrieval—all in a simplified workflow

Simpson’s Paradox is a statistical twist where trends reverse when data is combined, leading to misleading insights. Learn how this affects AI and real-world decisions

Understand the real-world coding tasks ChatGPT can’t do. From debugging to architecture, explore the AI limitations in programming that still require human insight

Confused between Data Science vs. Computer Science? Discover the real differences, skills required, and career opportunities in both fields with this comprehensive guide

A former Pennsylvania coal plant is being redeveloped into an artificial intelligence data center, blending industrial heritage with modern technology to support advanced computing and machine learning models
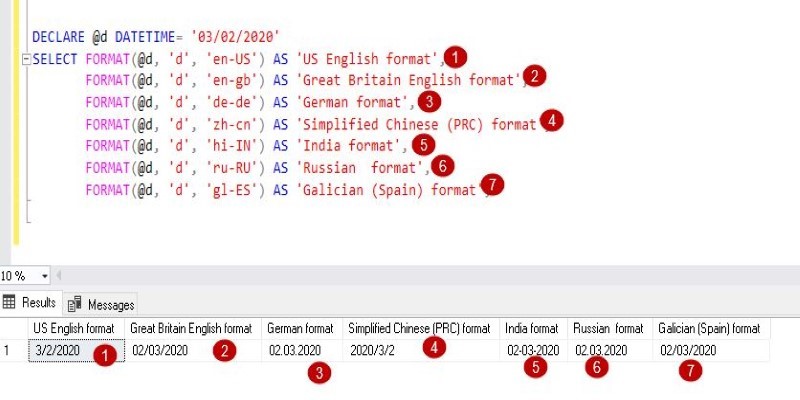
The FORMAT() function in SQL transforms how your data appears without changing its values. Learn how to use FORMAT() in SQL for clean, readable, and localized outputs in queries

Need to update your database structure? Learn how to add a column in SQL using the ALTER TABLE command, with examples, constraints, and best practices explained

Statistical Process Control (SPC) Charts help businesses monitor, manage, and improve process quality with real-time data insights. Learn their types, benefits, and practical applications across industries