Data today isn’t just about rows and columns — it’s about connections. Behind every social network, fraud detection system, or recommendation engine lies a web of relationships waiting to be explored. That’s why graph databases have become a vital tool in modern data engineering. But choosing the right one isn’t always easy. Neo4j vs. Amazon Neptune is a comparison that pops up often for teams building data-driven systems.
Both offer powerful ways to manage complex relationships, but their approaches, features, and ecosystems are strikingly different. This article unpacks those differences to help you decide which graph database fits your next project best.
When comparing Neo4j vs. Amazon Neptune, one of the clearest distinctions lies in data modeling and query language. Neo4j adopts a property graph model where data is stored as nodes and relationships, each capable of holding multiple properties. This setup allows for rich, flexible representations of complex connections. A major advantage is Cypher, Neo4j’s intuitive query language. Cypher reads almost like plain English, making it approachable for those familiar with SQL. Its simplicity and expressiveness have made Neo4j a favorite among developers, especially those new to graph databases or exploring relationship-driven data.
Amazon Neptune supports both property graphs and RDF (Resource Description Framework) triple stores. This allows users to choose between Gremlin, a traversal-based query language, or SPARQL, which is widely used for semantic web and knowledge graphs. However, Gremlin queries are often more verbose than Cypher, and SPARQL is tailored toward specific use cases like metadata management or ontology-based systems. While Neptune offers flexibility, this dual-model approach can introduce additional complexity for teams unfamiliar with these languages. Ultimately, Neo4j provides a developer-friendly experience, especially for transactional graph applications, while Amazon Neptune caters to enterprises seeking standards-based query support for specialized knowledge graph needs.
Architecture plays a vital role in the Neo4j vs. Amazon Neptune discussion, particularly around scalability and deployment models. Neo4j offers a versatile architecture, supporting both on-premise deployments and cloud-based solutions through Neo4j Aura. This allows businesses to choose between full infrastructure control or a fully managed service, depending on their environment. Neo4j’s causal clustering provides high availability and scalability by distributing data across leader and follower nodes, enabling better write and read performance in transactional systems.

Amazon Neptune is exclusively a managed service within the AWS ecosystem. It removes infrastructure management burdens by automating replication, backups, patching, and failover. This serverless approach appeals to organizations deeply invested in AWS. However, Neptune follows a single-writer, multiple-reader architecture, which can limit write scalability compared to Neo4j's multi-writer clustering in certain configurations. Neptune’s read replicas help scale read-heavy workloads, making it ideal for analytics use cases.
For hybrid or multi-cloud environments, Neo4j's flexibility is a clear advantage. For teams operating entirely within AWS, Neptune provides seamless integration with services like Lambda, CloudWatch, and IAM. The decision between these two platforms often boils down to infrastructure strategy—Neo4j offers customization and deployment freedom, while Neptune excels at simplicity within AWS's tightly controlled ecosystem.
Performance tuning and tooling greatly influence the Neo4j vs. Amazon Neptune debate in data engineering. Neo4j was purpose-built to handle densely connected graphs, enabling fast traversal across multiple relationship hops. Its native graph storage engine optimizes queries for complex data relationships, while its fine-grained indexing options help speed up read and write operations. Neo4j also provides visualization tools like Neo4j Browser and Bloom, giving developers immediate feedback during development and simplifying data exploration.
Amazon Neptune performs exceptionally well in large-scale graph environments, particularly those that demand high read scalability. Its design separates the writer from multiple read replicas, enabling horizontal scaling of read operations. However, this architecture may create performance limitations for write-intensive workloads due to its single-writer model. Neptune’s indexing is automatic, reducing operational overhead, but it limits customization options compared to Neo4j.
Tooling is another area where Neo4j shines, especially for teams building complex graph solutions from scratch. Neo4j’s development ecosystem includes SDKs, data import tools, and integrations with data science libraries. In contrast, Neptune lacks native visualization tools, often requiring third-party integrations for advanced graph analysis. For developers seeking robust tooling and in-depth control, Neo4j offers more, while Neptune emphasizes scalability and minimal configuration within AWS.
In the Neo4j vs. Amazon Neptune comparison, the choice often comes down to ecosystem alignment and specific use cases. Neo4j is widely adopted in scenarios where real-time relationship analysis is critical. Fraud detection, recommendation engines, supply chain optimization, and social networks are classic examples. Its integration with Apache Spark, Kafka, and machine learning frameworks extends its utility into data science pipelines. Neo4j’s focus on developer-friendly modeling and strong visualization tools makes it ideal for teams looking to build and iterate on graph models rapidly.

Amazon Neptune, however, thrives in large-scale, enterprise-grade environments, especially those already invested in AWS. Its strength lies in knowledge graphs, metadata management, security analytics, and cataloging systems. Neptune's RDF and SPARQL support make it particularly suited for semantic web applications, research databases, and healthcare or scientific knowledge graphs. Its compatibility with AWS services like S3, Glue, and SageMaker allows for easy integration into larger data engineering workflows.
Choosing between the two is rarely about raw performance alone—it’s about fit. If your team values flexibility, multi-cloud deployment, and a developer-first experience, Neo4j is often the better pick. If your architecture is fully AWS-native and prioritizes managed services with minimal operational complexity, Amazon Neptune becomes the more strategic choice.
In the end, choosing between Neo4j and Amazon Neptune comes down to your project’s priorities. If you need developer-friendly tools, flexible deployment, and rich data modeling, Neo4j delivers. If seamless AWS integration, scalability, and managed infrastructure are key, Amazon Neptune fits better. Both offer strong graph capabilities for data engineering. The best choice isn’t about features alone—it’s about how well the tool fits your ecosystem, skills, and long-term goals. Pick the one that aligns with your real-world needs.

Building smart AI agents with LangChain enables developers to create intelligent agents that remember, reason, and act across multiple tools. Learn how the LangChain framework powers advanced prompt chaining for real-world AI automation
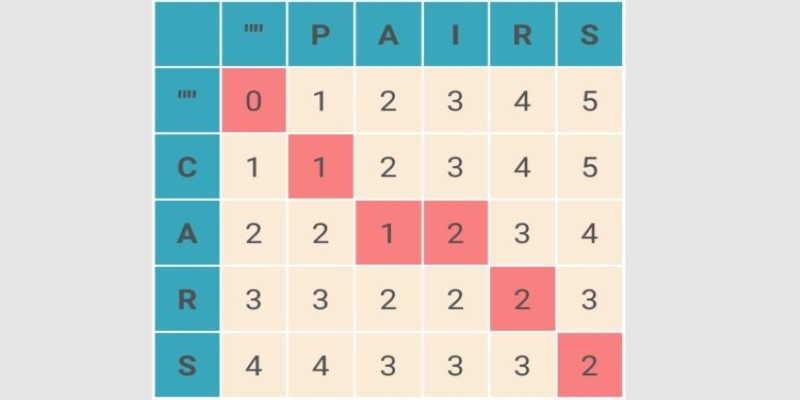
What Levenshtein Distance is and how it powers AI applications through string similarity, error correction, and fuzzy matching in natural language processing

Confused between Data Science vs. Computer Science? Discover the real differences, skills required, and career opportunities in both fields with this comprehensive guide
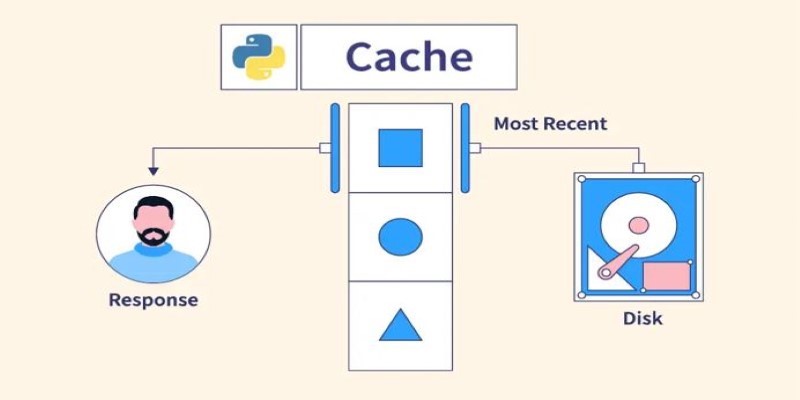
Understand what Python Caching is and how it helps improve performance in Python applications. Learn efficient techniques to avoid redundant computation and make your code run faster

Statistical Process Control (SPC) Charts help businesses monitor, manage, and improve process quality with real-time data insights. Learn their types, benefits, and practical applications across industries

A former Pennsylvania coal plant is being redeveloped into an artificial intelligence data center, blending industrial heritage with modern technology to support advanced computing and machine learning models

Learn how process industries can catch up in AI using clear steps focused on data, skills, pilot projects, and smart integration

Need to update your database structure? Learn how to add a column in SQL using the ALTER TABLE command, with examples, constraints, and best practices explained

Gen Z embraces AI in college but demands fair use, equal access, transparency, and ethical education for a balanced future

Discover how DataRobot training empowers citizen data scientists with easy tools to boost data skills and workplace success

Wondering whether to use Streamlit or Gradio for your Python dashboard? Discover the key differences in setup, customization, use cases, and deployment to pick the best tool for your project

IBM’s Project Debater lost debate; AI in public debates; IBM Project Debater technology; AI debate performance evaluation