Every second, data is generated at staggering volumes — clicks on a website, sensors reporting temperature, and trades executed on stock exchanges. Waiting minutes or hours to process this information often isn't an option. Apache Storm was built for these moments, offering a way to process streams of data instantly and at scale.
Unlike batch systems that process static chunks, Storm handles live, continuous streams, making it indispensable for systems that need to react in real time. This guide walks through its fundamental concepts, architecture, real-world uses, and how to set up and run a Storm topology effectively on your infrastructure.
Apache Storm is designed to handle endless streams of data by organizing them into a clear, flexible workflow called a topology. Think of a topology as a live blueprint that maps out how data moves through each stage of processing and how the work gets divided. Storm spreads this work across a cluster of machines, letting multiple parts of the workflow run in parallel and recover seamlessly if something fails.
At the heart of a topology are two types of components: spouts and bolts. Spouts act as data feeders, pulling records — called tuples — from sources like message queues, log files, or databases, and streaming them into the system. Bolts do the heavy lifting: they transform, filter, aggregate, or otherwise process the tuples before passing them along. Together, they form a directed acyclic graph, with each stage representing a specific processing step.
Unlike batch systems, Storm topologies are designed to keep running indefinitely, making them perfect for building pipelines that stay current with real-time data as it arrives.
An Apache Storm cluster consists of a master node and several worker nodes. The master runs a daemon called Nimbus, which coordinates the cluster by distributing code, assigning tasks, and recovering from failures. Nimbus itself doesn’t process data. Each worker node runs a Supervisor daemon that manages worker processes, which are responsible for executing spouts and bolts.
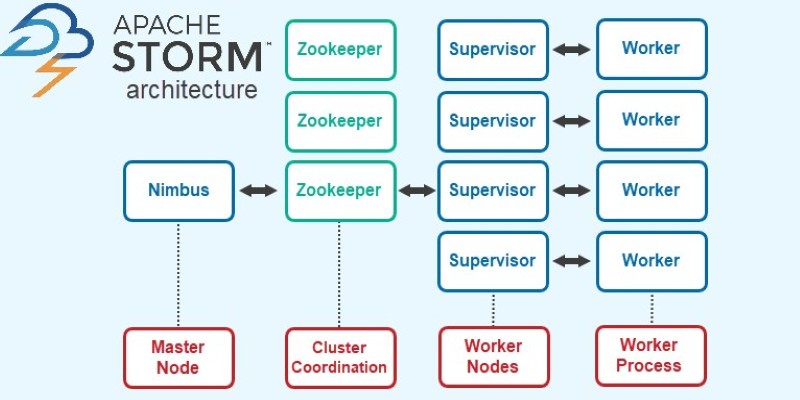
Each worker process runs one or more executors, which are threads assigned to specific tasks. A task is a single instance of a spout or bolt. This structure provides flexibility and allows for high parallelism. You can increase throughput simply by increasing the number of workers or tasks.
Storm provides several stream grouping strategies to control how data flows between components. Shuffle grouping distributes tuples randomly, while fields grouping ensures tuples with the same field value go to the same bolt instance, preserving data relationships when needed.
The system is fault-tolerant by design. If a worker crashes, Nimbus reassigns its tasks to other available workers. Storm’s acknowledgment system can track each tuple and retry it if a failure occurs, minimizing data loss. This makes it reliable for mission-critical applications that require accurate results even in the face of hardware or software failures.
Apache Storm is used across industries wherever real-time data processing is required. In analytics, it powers dashboards that display current metrics like user counts, click-through rates, or system errors. Data is processed as it arrives, enabling operators to spot trends and respond without delay.
It is widely used for monitoring and alerting. System logs and metrics are ingested and analyzed in real time, so anomalies and potential failures can trigger automatic alerts and corrective actions. This is common in IT operations, telecommunications, and cloud services.
Financial services use Storm to process trades, detect fraudulent transactions, and update portfolios on the fly. Its ability to handle high-throughput, low-latency streams helps institutions respond to market changes as they happen.
In manufacturing and IoT, Storm processes sensor data from equipment to monitor conditions and optimize workflows. This can reduce downtime and improve efficiency by reacting immediately to signals from the production floor. Similarly, many online services use Storm to power recommendation engines and content personalization by analyzing user behavior in real time and adjusting results dynamically.
Getting started with Apache Storm involves setting up a cluster, writing a topology, and submitting it for execution. Storm supports two modes. In local mode, you can test topologies on a single machine. Cluster mode distributes the workload across multiple servers for production deployments.
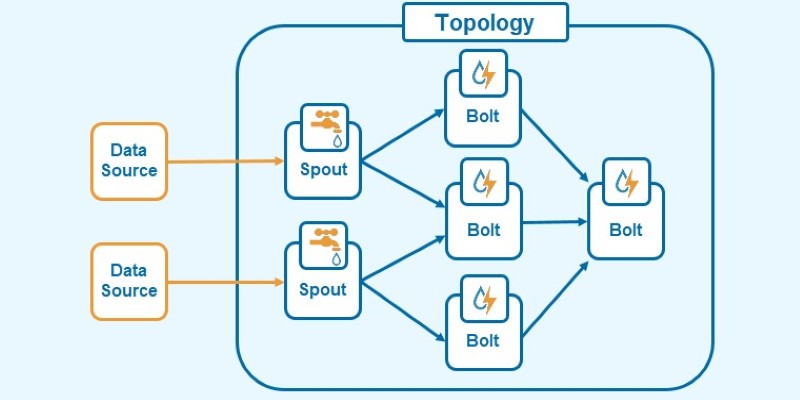
Writing a topology means defining your spouts and bolts, connecting them in the desired processing graph, and specifying parallelism levels. Storm provides a Java API, though libraries for other languages like Python are available. Once written and compiled into a JAR file, the topology is submitted using the Storm command-line tool, which sends it to Nimbus. Nimbus then assigns tasks to the Supervisors, and the topology begins running.
The Storm UI is a web-based dashboard for monitoring clusters. It shows details about running topologies, task throughput, latency, and any errors. You can use it to adjust settings, monitor system health, and terminate or restart topologies when needed.
Storm integrates seamlessly with other big data tools. It can read streams from Kafka, process them, and write results to storage systems like HDFS, Cassandra, or Elasticsearch. This makes it easy to build flexible, end-to-end data pipelines using existing infrastructure.
Apache Storm is a reliable choice for processing data streams with low latency and high scalability. Its simple yet powerful model of spouts and bolts allows developers to create workflows that process information as it arrives. The distributed architecture makes it fault-tolerant and easy to scale horizontally. With its ability to integrate with popular data sources and sinks, Storm remains a strong option for real-time analytics, monitoring, financial systems, and IoT applications. For teams looking to build systems that stay responsive to a continuous flow of data, Apache Storm offers a clear and effective framework that has stood the test of time.

Discover how DataRobot training empowers citizen data scientists with easy tools to boost data skills and workplace success

Fujitsu AI-powered biometrics revealed at Mobile World Congress 2025 claims to predict crime before it happens, combining real-time behavioral data with AI. Learn how it works, where it’s tested, and the privacy concerns it raises

How self-driving tractors supervised remotely are transforming AI farming by combining automation with human oversight, making agriculture more efficient and sustainable

How the Chain of Verification enhances prompt engineering for unparalleled accuracy. Discover how structured prompt validation minimizes AI errors and boosts response reliability

Accessing Mistral NeMo opens the door to next-generation AI tools, offering advanced features, practical applications, and ethical implications for businesses looking to leverage powerful AI solutions

How to use MongoDB with Pandas, NumPy, and PyArrow in Python to store, analyze, compute, and exchange data effectively. A practical guide to combining flexible storage with fast processing

A former Pennsylvania coal plant is being redeveloped into an artificial intelligence data center, blending industrial heritage with modern technology to support advanced computing and machine learning models

Find out the key differences between SQL and Python to help you choose the best language for your data projects. Learn their strengths, use cases, and how they work together effectively

How the AI Robotics Accelerator Program is helping universities advance robotics research with funding, mentorship, and cutting-edge tools for students and faculty

Looking for the best Airflow Alternatives for Data Orchestration? Explore modern tools that simplify data pipeline management, improve scalability, and support cloud-native workflows

How COUNT and COUNTA in Excel work, what makes them different, and how to apply them effectively in your spreadsheets. A practical guide for clearer, smarter data handling

Wondering whether to use Streamlit or Gradio for your Python dashboard? Discover the key differences in setup, customization, use cases, and deployment to pick the best tool for your project