Advertisement
Behind AI tools that "understand" language is one simple idea: numbers. Specifically vector embeddings. These are dense, multi-dimensional arrays of numbers that help machines compare meaning in language. If you're working with chatbots, recommendation engines, or search tools, you'll deal with embeddings sooner or later.
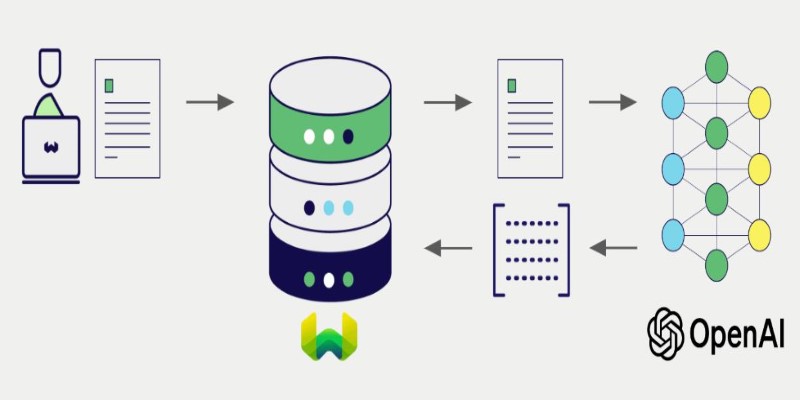
But raw embeddings aren’t enough—you need to generate them, store them, and make them searchable. That's where LangChain enters the picture. It helps you compute vector embeddings with LangChain using models like OpenAI or Hugging Face and store them in vector databases like FAISS, Chroma, or Pinecone. This guide breaks the process down step by step—no fluff, just the core mechanics.
Vector embeddings transform text into numerical vectors that carry semantic meaning. Two similar sentences generate vectors that are close together in vector space. This idea powers many AI systems—from semantic search to retrieval-based question answering.
LangChain is a framework built around language models, but its real strength lies in how it connects those models with embedding generation and vector storage. With LangChain, you don't have to write a boilerplate for tokenization, encoding, or indexing. Instead, you use its built-in tools to compute embeddings and plug them into various vector stores.
For example, if you're building a Q&A chatbot over a document base, the pipeline is straightforward: split text, embed it, store it, and retrieve relevant chunks later using semantic similarity. LangChain streamlines every part of that process. You choose an embedding model, pass in your text, and get back vector data that can be stored and searched.
LangChain makes embedding generation pretty straightforward, assuming you have your environment set up. First, you need an embedding model. LangChain supports several, including OpenAIEmbeddings, HuggingFaceEmbeddings, and more. You start by importing the model you want and initializing it with your API key or configuration.
Here’s a basic example using OpenAI:
from langchain. embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
vector = embeddings.embed_query("LangChain simplifies AI pipelines.")
That one-line embed_query is where the text is converted into a numerical vector—a dense array of floating-point numbers. These vectors are typically 1536-dimensional (for OpenAI's text-embedding-ada-002 model), which gives you enough room to capture subtle semantics.
But embedding alone isn’t useful unless you’re storing the result. That’s where the vector store comes in. LangChain supports many options for storage. The two most developer-friendly ones are FAISS and Chroma. FAISS is great for local setups, while Chroma provides more indexing features out of the box.
To compute multiple embeddings from a list of texts:
texts = ["LangChain is great for vector search.", "Embeddings are numeric representations.", "Vector stores are essential for retrieval."]
vectors = embeddings.embed_documents(texts)
Now, you've turned a list of sentences into a list of embeddings, ready to be stored and searched.
LangChain takes care of the backend calls to the embedding model. You don’t need to manage batching, format conversions, or tokenizer intricacies—just supply the text, and you get usable vectors. This simplicity helps you focus on your application logic instead of ML plumbing.
Once you’ve computed embeddings, the next task is storing them. LangChain's vector store abstraction allows you to persist these vectors along with metadata. Whether you use FAISS, Chroma, or Pinecone, the process follows a similar structure.
Here’s how to store vectors using FAISS:
from langchain.vectorstores import FAISS
from langchain.docstore.document import Document
docs = [Document(page_content=text) for text in texts]
db = FAISS.from_documents(docs, embeddings)
At this point, db is your vector index. Each document is embedded and stored with its metadata. You can now perform a similarity search using the following:
query = "What is LangChain used for?"
results = db.similarity_search(query)
LangChain converts the query to an embedding and compares it against stored vectors. The results include the original documents that are most similar to the query—perfect for semantic search or knowledge-based agents.
If you want persistence—meaning your vector database survives a reboot—you can save and reload it like this:
db.save_local("faiss_index")
# Later...
db = FAISS.load_local("faiss_index", embeddings)
This functionality is critical for production apps. This means you can index the vectors once and reuse them across sessions or deployments. For cloud-scale deployments, you can switch from FAISS to Pinecone or Weaviate with minor changes to your code—LangChain’s interface stays consistent.
LangChain supports metadata tagging, letting you attach details like author, creation date, or topic to each Document object. This added context helps refine searches by enabling filters based on metadata, making results more relevant and organized for deeper, more accurate information retrieval.
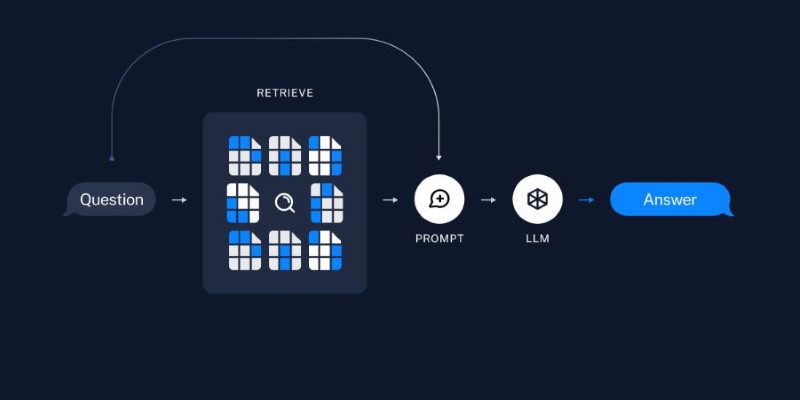
Embedding and storing are the foundation. However, the real power is shown when you combine it with a language model using Retrieval-Augmented Generation (RAG). This approach fetches relevant documents based on a query and uses them to generate a grounded, context-aware answer.
With LangChain, this is just a few lines:
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
qa = RetrievalQA.from_chain_type(llm=OpenAI(), retriever=db.as_retriever())
answer = qa.run("How does LangChain handle embeddings?")
Here, your question is embedded, relevant documents are fetched from the vector store, and the model uses them to generate an answer. This reduces hallucination and creates more accurate outputs, which is especially helpful in knowledge-heavy domains.
LangChain handles the flow: it computes the query embedding, finds similar documents, merges the content into a prompt, and gets a response from the model. You can extend this by adding memory, custom prompts, or chaining additional tools, all within LangChain’s framework.
This setup—embeddings plus vector store plus LLM—forms the base of many advanced AI apps. And LangChain ties it together seamlessly.
Vector embeddings are essential to AI systems that interpret and retrieve language effectively. LangChain makes it easy to compute, store, and search these embeddings through a consistent and simplified workflow. From generating vectors to managing them across vector stores, it streamlines complex steps into manageable parts. Paired with retrieval-based generation, LangChain enables smarter, context-aware applications. Whether you're building a chatbot or a semantic search tool, this approach opens the door to advanced AI development with less hassle and more flexibility.
Advertisement

Learn how process industries can catch up in AI using clear steps focused on data, skills, pilot projects, and smart integration

What Hannover Messe 2025 has in store, from autonomous robots transforming manufacturing to generative AI driving innovation in industrial automation

Stay updated with AV Bytes as it captures AI industry shifts and technological breakthroughs shaping the future. Explore how innovation, real-world impact, and human-centered AI are changing the world

How the Chain of Verification enhances prompt engineering for unparalleled accuracy. Discover how structured prompt validation minimizes AI errors and boosts response reliability

Confused between Data Science vs. Computer Science? Discover the real differences, skills required, and career opportunities in both fields with this comprehensive guide

Discover how DataRobot training empowers citizen data scientists with easy tools to boost data skills and workplace success

How to use MongoDB with Pandas, NumPy, and PyArrow in Python to store, analyze, compute, and exchange data effectively. A practical guide to combining flexible storage with fast processing

Uncover the best Top 6 LLMs for Coding that are transforming software development in 2025. Discover how these AI tools help developers write faster, cleaner, and smarter code

Wondering whether to use Streamlit or Gradio for your Python dashboard? Discover the key differences in setup, customization, use cases, and deployment to pick the best tool for your project
How the SUMPRODUCT function in Excel can simplify your data calculations. This detailed guide explains its uses, structure, and practical benefits for smarter spreadsheet management

Understand the Difference Between Non Relational Database and Relational Database through clear comparisons of structure, performance, and scalability. Find out which is better for your data needs

Learn Apache Storm fundamentals with this detailed guide covering architecture, key concepts, and real-world use cases. Perfect for mastering real-time stream processing at scale